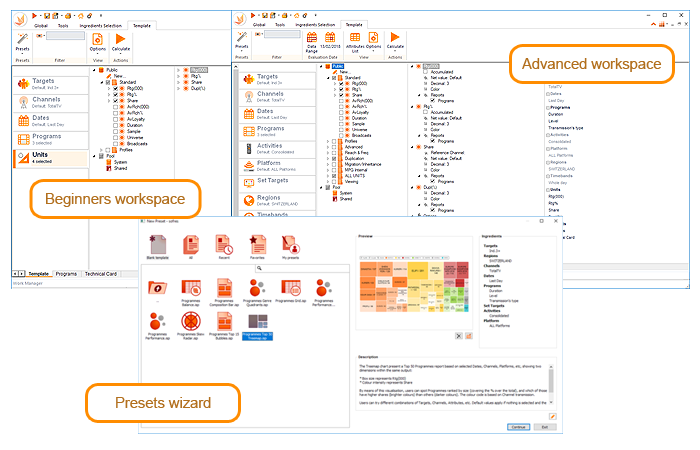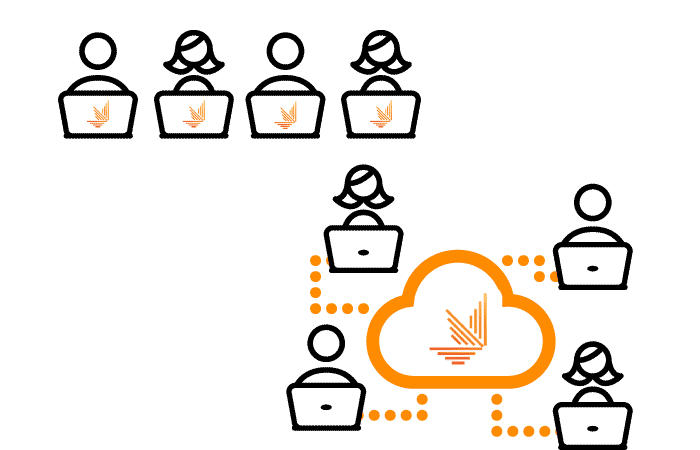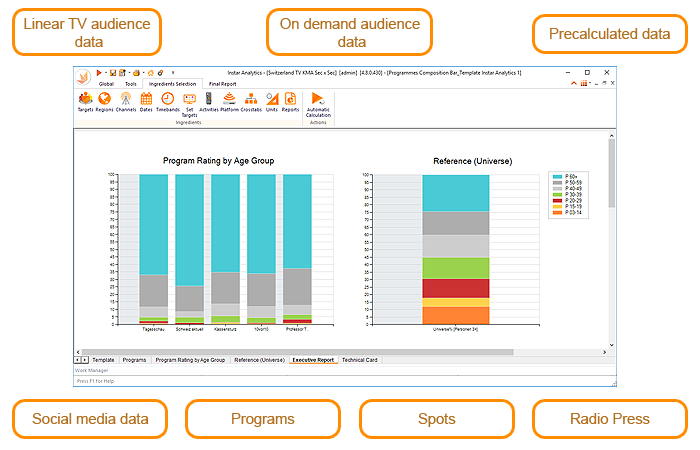
The households in the dataset are split into N partitions, with an algorithm which tries to distribute the households in the most efficient way possible. These partitions will have identical or very similar number of households
One or more calculation nodes use each partition, and the Job distributor will balance the workload between the available slave replicas, providing the best performance. If more concurrent users are needed, more calculation nodes can be launched to cover this extra workload (permanently or just for high-demand peaks).
In case of failure of one calculation node, their replicas will handle their calculations, providing reliability for the final user in a transparent way.